In this post, we will be looking at the classification technique known as Support Vector Machine (SVM). SVM is one of the most effective classification algorithms and is often found difficult to understand primarily because there are various kinds of concepts that are involved at play.
So far the algorithms that we have looked at (Linear and Logistic Regression) rely on Gradient Descent to achieve optimal values. However, SVM is slightly different. We will be using gradient here as well but not exactly in the same manner.
Introduction
SVM gives us an option to transform the data into a higher dimension. It runs on an idea that if data is not linearly separable, we move to a higher dimension to find a plane that can separate the data linearly. In lower dimension, this might appear to be a non-linear plane. The reason it is called support vector machine is because the identified separator plane uses the nearest data points of each class to classify and these data points are called support vectors. This way, we are using the data point from class 1 that is most similar to class 2 and similarly the other way. The image below depicts this information.
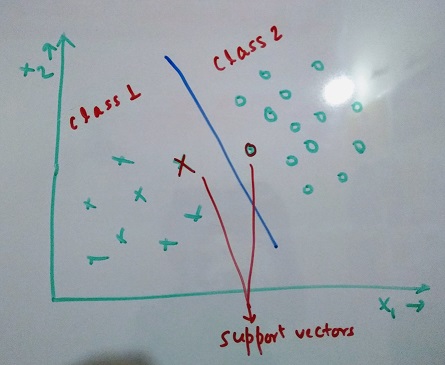
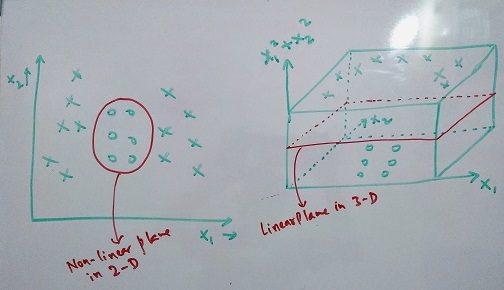
In the above image the points nearest to the plane are called support vectors. Below is an example of how changing the data to higher dimension helps separate the classes.
Pre-Requisites
There are certain prerequisites that one should know before understanding how SVMs work. Let’s look at them -
- Vectors and Planes -
-
Equation of a plane P : ax + by + cz = k (3-dimensional)
-
Normal Vector to the plane P (Vector perpendicular to the plane) : aî + bĵ + ck̂
-
Distance of a point Q(x1,y1,z1) from the plane P : ± (ax1 + by1 + cz1 -k) ⁄ √(a2 + b2 + c2)
The distance would be represented with a modulus but the value itself would be (+) or (-) depending on which side of the plane the point lies.
-
Gradient - Gradient of a function is a vector that points towards the maximum increase of the function
-
General Fact - minx maxα f(x,α) ≥ maxα minx f(x,α)
-
Lagrangian Method - This method is used to find optimal values of a function subject to certain constraints.
Initial Form
Objective function : minx f(x)
Equality Constraint : h(x) = 0
In order to solve this, we need to understand that the minima of f(x) will occur when both f(x) and h(x) are tangential to each other. ⇒ ∇x f = -λ (∇x h) (λ can be positive or negative)
therefore, in order to solve this problem, we define a new Lagrangian function, ℒ(x,λ) = f(x) + λ(h(x))
Now, our objective is to just minimize this function. The conditions for this would be -
∇x ℒ = 0 and ∇λ ℒ = 0
⇒ ∇x f = 0 and h(x) = 0 (This was our original condition as well).
The λ here is called lagrangian multiplier and represents ∇ ℒ ⁄ ∇ h (The rate of increase of ℒ as we relax the conditions on h)
Ext1 : It has been shown that this can be extended for multiple constraints as well which is shown below -
Objective function : minx f(x)
Equality Constraint : hi(x) = 0 where i = {1,2,3,…,n}
In this case, the Lagrangian function would be : ℒ(x,λ1,λ2,…,λn) = f(x) + Σλi hi(x)
Ext2 : Another extension of this is when we introduce inequality constraint instead of equality constraint into the picture.
Objective function : minx f(x)
Inequality Constraint : g(x) ≤ 0
New Lagrangian function - ℒ(x,α) = f(x) + α(g(x))
Here, if the x at which f(x) achieves minima satisfies the condition g(x) < 0 ⇒ the constraint is not required and α can be set to 0. If not, then again the minima will occur where both the functions are tangential to each other and so, g(x) = 0 (because the intersection point will lie on g(x))
⇒ α(g(x)) = 0 always and hence the function’s value at minima is again same as minima of f(x). α here is called KKT multiplier (KKT stands for Karush-Kuhn-Tucker)
Ext3 : Generalizing with both equality and inequality constraints -
Objective function : minx f(x)
Equality Constraint : hi(x) = 0 where i = {1,2,3,…,n}
Inequality Constraint : gj(x) = 0 where j = {1,2,3,…,m}
The Lagrangian function in this case would be, ℒ(x,λ1,λ2,…,λn,α1,α2,…,αm) = f(x) + Σλi hi(x) + Σαj gj(x)
- Primal and Dual Form - These are two forms of objective function and we are going to look at them using the generalized form mentioned above in Ext3.
Primal Form -
ℒ(x,λ1,λ2,…,λn,α1,α2,…,αm) = f(x) + Σλi hi(x) + Σαj gj(x) subject to the corresponding equality and inequality conditions.
The primal form is : θp(x) = maxα,λ ℒ(x,λ,α)
If the x satisfies the constraints, then θp(x) = f(x) as all the other terms are 0. So, our problem becomes, minx θp(x) = min f(x) = p
Dual Form -
ℒ(x,λ1,λ2,…,λn,α1,α2,…,αm) = f(x) + Σλi hi(x) + Σαj gj(x) subject to the corresponding equality and inequality conditions.
The Dual form is : θd(α,λ) = minx ℒ(x,λ,α)
So, entire problem, maxα,λ minx ℒ(x,λ,α) = d
From the general fact mentioned above, minx maxα f(x,α) ≥ maxα minx f(x,α)
Comparing this with our situation, d ≤ p
The two values d and p are equal when they staisfy a set of condition called KKT conditions. Following are the condition,
i. ∇x ℒ = 0
ii. ∇λ ℒ = 0
iii. αj ≥ 0
iv. gj ≤ 0
v. αj gj = 0
All these conditions are satisfied in our case and hence, we can solve the dual form instead of primal form if the primal form turns out to be a non convex problem and cannot be solved.
Notation
The Notations used for SVM is slightly different from that of logistic regression where we used 0 and 1 for representing success and failure. SVM uses {-1, +1} for differentiating between classes. This technique uses vector approach and identifies a plane that separates both classes from each other.
Theory (Problem Formulation)
First we look at how SVM uses the data in it’s current form to identify the separation plane and then see how we can use it to transform the data into higher dimension. Since, we are using a plane to separate the classes. The objective function will be the equation of a plane.
h(w,b) = wTx + b (This is the equation of a plane in linear algebra form and is equivalent to ax + by + cz + k = 0 in 3-D)
where w = [θ1,θ2,…,θn], x = [x1,x2,…,xn] and b = θ0 in n-Dimnesion.
The objective is to maximize the distance between the nearest data point of each class (support vectors) and the plane. Below is an image showing a linearly separable dataset.
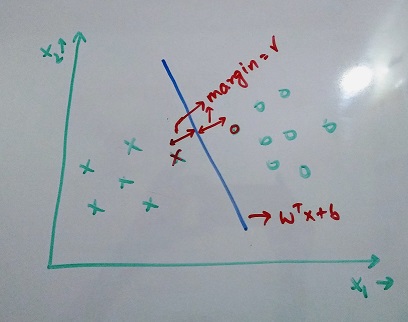
Also, y(i)(wTx(i) + b) > 0 ⇒ data point correctly classified (If data point is on left side of the plane, the distance will be negative and if on the right side, it will be positive. This coupled with the notation of {-1, +1} always results in positive number for correct classifications)
Note: the denominator of distance has been omitted here as it is always positive (equivalent to √(a2 + b2 + c2))
This metric is called functional margin, γ̂ (i) = y(i)(wTx(i) + b)
There is another metric called geometric margin, γ(i) = γ̂ (i) ⁄ ||w||
Let’s denote γ = min γ(i)
Defining Objective
So, our objective function would be, max γ, w,b γ subject to constraint y(i)(wTx(i) + b) ⁄ ||w|| ≥ γ
This basically means, we want to maximize the minimum margin with constraint that the distance between every data point and the plane is greater than or equal to this value. Representing this in the form of functional margin,
max γ, w,b γ̂ ⁄ ||w|| subject to constraint y(i)(wTx(i) + b) ≥ γ̂
This problem is not solvable in its current form and hence, we need to perform certain manipulations. Notice in the definition of functional margin, γ̂ (i) = y(i)(wTx(i) + b), if we change w → 2w and b → 2b ⇒ γ̂ → 2γ̂
This shows that it’s possible to choose a proportional value and rescale the entire objective to have maximum functional margin = 1. Therefore, on rescaling we get our objective function as,
max γ, w,b 1 ⁄ ||w|| subject to constraint y(i)(wTx(i) + b) ≥ 1
This will be same as, min γ, w,b ||w||2 ⁄ 2 subject to constraint y(i)(wTx(i) + b) ≥ 1
Theory (Problem Solution)
Lagrangian Method
In order to solve our problem, we will be using the Lagrangian Method described above in the pre-requiste section. Here, we have an objective function we want to minimize subject to an inequality constraint.
So, objective function : f(w) = ||w||2 ⁄ 2
Inequality constraints : gi(w,b) = - y(i)(wTx(i) + b) + 1
Therefore, we define a lagrangian function, ℒ(w,b,α) = ||w||2 ⁄ 2 - Σim αi [y(i)(wTx(i) + b) - 1]
Conditions to minimize the lagrangian is, ∇w L = 0 and ∇b L = 0
Applying these conditions, we get, w = Σi=1m αi y(i) x(i) and Σi=1m αi y(i) = 0 - (Reference Equation 1)
Once, we get w (the value that decide the orientation of the plane), to obtain b (decides the parallel movement of plane) is easy. The plane would be at the mid point of the distance between closest data points of both classes (No class gets priority).
So, b = maxy = -1 wTx(i) + miny = 1 wTx(i) ⁄ 2
Also, replacing the value of w in our prediction function, wTx + b = (Σi=1m αi y(i) x(i))x + b
⇒ wTx + b = Σi=1m αi y(i) (x(i))Tx + b
Observe the term, (x(i))Tx. This is the product of training data points and new data point to be classified. It is also written as <x(i),x> and is also called inner product.
If we look carefully at the prediction function, the value of αi = 0 whenever gi(w,b) ≠ 0 (Refer Prerequisite above) and hence, the prediciton will only depend on those training data points where gi(w,b) = 0. This happens only for the data points closest to the plane. This is the reason these closest data points are called support vectors.
Now, the only thing unknown to us is αi. For this, we will be using the primal and dual form explained above in the pre-requisite section.
Primal and Dual Form
Primal Form of the Lagrangian function, θp = maxα ℒ(w,b,α) = f(w,b)
So the objective becomes : minw,b f(w,b) (This is again not solvable. Hence, we resort to Dual form of the problem)
and Dual Form of the Lagrangian function, θd = minw,b ℒ(w,b,α)
Let’s solve the Lagrangian first by using value of w obtained above in order to calculate θd
ℒ(w,b,α) = ||w||2 ⁄ 2 - Σi=1m αi [y(i)(wTx(i) + b) - 1]
⇒ ℒ(w,b,α) = (Σi=1m αi y(i) x(i))(Σj=1m αj y(j) x(j)) ⁄ 2 - Σim αi [y(i) { (Σj=1m αj y(j) x(j)) x(i) + b} - 1]
⇒ ℒ(w,b,α) = (Σi,j=1m αiαj y(i)y(j) (x(i))T x(j)) ⁄ 2 - Σi,j=1m αiαj y(i)y(j) (x(i))T x(j) - b Σi=1m αi y(i) + Σi=1m αi
From Reference Equation 1 above, the third term is 0
⇒ ℒ(w,b,α) = Σi=1m αi - (1⁄2)Σi,j=1m αiαj y(i)y(j) (x(i))T x(j)
Now, the above equation is only a function of αi. So pluging this into our dual form,
maxα θd(α) = maxα Σi=1m αi - (1⁄2)Σi,j=1m αiαj y(i)y(j) (x(i))T x(j) subject to contraints αi ≥ 0 and Σi=1m αi y(i) = 0
⇒ maxα θd(α) = maxα Σi=1m αi - (1⁄2)Σi,j=1m αiαj y(i)y(j) <x(i),x(j)> subject to contraints αi ≥ 0 and Σi=1m αi y(i) = 0
SMO Algorithm
The way we solve this is, we vary two α’s at a time and optimize the function according to it (We cannot vary one at a time because varying one keeping others constant would violate the second constraint). So, vary α1 and α2 together.
α1y1 + α2y2 = k
⇒ α1 = (k - α2y2) ⁄ y1
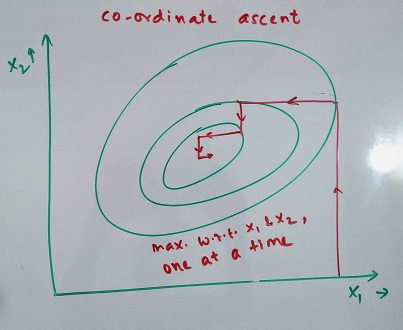
therefore, θd(α) will be of the form aα22 + bα2 + c which is a solvable quadratic equation. Post this, we will maximize the function for another set of α’s. This is called as Sequential Minimal Optimization (SMO Algorithm). Following image describes how this would work when varying one α at a time in 2-D (Coordinate Ascent Algorithm)
Kernels
A very important point to notice above is in both the prediction function and the final objective function, the involvement of data point is in their inner product form <x(i),x(j)>. The values x(i) and x(j) here are the feature sets of data and this form helps us as we can just replace them with any other feature set and nothing else needs to change. The other feature set is generally one with a higher dimension and is represented in inner product form as <Φ(x)(i),Φ(x)(j)>.
This higher dimension can be computationally very inefficient and might take very long time to calculate but what if we could somehow represent this inner product through some function that can be computed very easily. These functions are called Kernal function. Let’s take an example for this -
Let K(x,z) = (xTz)2
⇒ K(x,z) = (Σi=1m xizi) (Σj=1m xjzj)
⇒ K(x,z) = Σi,j=1m (xixj)(zizj)
So, if we consider x to be in 3-D, here Φ(x) = [x1x1, x1x2, x1x3, x2x2, x2x3, x3x3]
By considering the Kernel function mentioned above, we moved from 3-D to 6-D space. Also, this way instead of calculating the Φ(x), we directly calculate the inner product which is computationally very efficient.
There are lots of commonly used Kernel functions with the most common being Guassian Kernel, K(x,y) = exp(- ||x - y||2 ⁄ 2σ2)
In order to see the φ(x) for guassian kernel, we can use taylor expnasion for exp(x). This will show us that this kernel takes our data to infinite dimensional space.
End Notes
I would recommend going through the derivations by writing them yourself as that would clear up a lot of concepts. Let me know if any clarifications are needed in the comments section below.
I would be adding implementation of SVM on a dataset shortly.